ソフトウェアエンジニアリング協会のコーディング練習会に参加して、ビッグテックの仕事の一端を見る
一般社団法人 ソフトウェアエンジニアリング協会が主催する、オンラインのコーディング練習会に参加した。同協会は、世界で戦える日本のソフトウェアエンジニアを増やすため、育成や就職支援を非営利で実施している。特に団体化の前の活動として、エンジニア実務未経験の医師を指導しGoogleに入社させた記事が有名であろう。
私は2025年9月から半年ほど育児休業を取得していたが、休業中のブランクを軽減し、復帰後に高いパフォーマンスを発揮するため、この練習会が有益だと考えた。というのも、研究職からキャリアをスタートし、R&Dのエンジニアを経て機械学習エンジニアとして勤務してきたが、ソフトウェアエンジニアとしてのスキルや知識は「虫食い」で、基礎を固めたいという思いがあった。また今後、コードを書くこと自体は生成AIをはじめとするツールによって生産量が爆発的に増えるであろうから、そのようなツールを使わなくても手で書ける、かつツールの誤動作に気がつける、という状態になっておくことが重要だと思った。
続きを読むPixel10が発売されたけど、せっかくだから俺はこのPixel8を選ぶぜ!!
2年前(2023年)から利用してきたPixel8を買い直して、もう2年ほど使い続けることにした。自身の思考整理と、似たような境遇の方の参考になるかもしれないと思って、書き残しておく。
前提として、コンパクトなスマートフォンが好きだ。遡れば初スマートフォンがAQUOS PHONE ZETA SH-06Eで、SonyのXperia Z3 Compact SO-02GとかXperia X Compact SO-02Jなどを経て、(比較的)最近ではGoogle Pixel3と5を愛用していた。パンツのポケットに無理なく収まり、さっと取り出して片手で操作できるのがいいのだ。
このコンパクト好きの流れで、2023年にPixel8を入手した。auにMNPしスマホトクするプログラムを利用することで、毎月430円で2年間(つまり都合9,890円)という破格の価格で運用できていた。来月からは残債75,350円をもう2年で分割返済することになる(つまり3,139円/月)が、中古市場を見ても美品で5万円切りの同機種が出回っており、現在の端末は返却したほうが良い。
まず思いついたのは、もう一度MNPのパワーを利用して最新のPixelを入手することだ*1。Googleは長らく*2シェアを広げるために投げ売…ディスカウントを推進しており、2025年に発売されたPixel 10シリーズでもその流れは続いている。前述のプログラムを適用すると、965円/月で2年間(都合23,160円)利用でき、残債は61,740円である(2,572円/月を2年間)。2万円ちょっとで最新機種が使えるというのは魅力的に思える。
Pixel8から10へのアップデートをまとめてみる。9も未チェックだったのでこのついでに。
https://www.gsmarena.com/compare.php3?idPhone1=13979&idPhone2=13219&idPhone3=12546
※以下画像は上記URLのスクリーンショットである。左からPixel10, 9, 8.
まず、本体サイズは9から一回り大きくなっている。重量は200gを超えており、取り回しは悪くなっていそうだ。

次にCPU. チップセットは2世代進んでいる一方で、ベンチマークスコアは大差なさそう。バッテリーライフは1時間ほど悪化している。今後のアップデートで修正される可能性はあるが、現時点ではネガティブだ*3。画面の輝度が改善し、特に直射日光下での視認性が改善したそうだが、生憎困った場面が思い浮かばない。

最後はカメラ。10からは無印でも5倍望遠が増えた。一方で、メインである広角のセンサーサイズは縮小している。センサーサイズが大きいほど、単位時間で取り込める光量が多くなるために暗所撮影に強く、ダイナミックレンジが広く、背景がボケやすいというメリットがある。この差は日常でおそらく体感できないが、私は一度スペックを知ってしまうと何となくテンションが下がってしまうタイプだ(反対も然り)。ちなみに8から9では、広角は変化無し、超広角のセンサーサイズが向上している。

まとめると、現有の8から2世代進んだにもかかわらず、10ではメインカメラのセンサーサイズが縮小し・バッテリーライフが短くなり・大きく重くなる一方で、光学望遠が手に入る、ということになる*4。こうなると、これまで望遠が欲しいと思ったシーンがさほどない私としては、乗り換えるメリットが「8の残債を払い続けるよりは安い」くらいしかない。関連する手続きの多さを考えるとさらに気が重くなる。
それならば同機種を買い直すことを考える。前述の通り中古ショップでは5万円弱のものがあるが、フリマサイトではタイミングによっては・クーポンを組み合わせることで4万円前半で購入できる。また、現時点で発売から4年経過したPixel 6の売価は2万円弱だった。多少乱暴だが、もう2年だけPixel 8を利用したあとの売価のベンチマークとすると、差し引き2万円程度になる(煩雑な手続きが伴う10と同等だ!)。アップデートも2030年10月まで保証されているので安心だ。
ちなみにコンパクトタイプの有力候補として、Samsung Galaxy Sシリーズも挙げられる。こちらは、チップセットが高性能である・よりコンパクトであることがメリットな一方で、Pixel 10よりもさらに小さいセンサーサイズであること・実質負担がやや高い*5ことから不採用となった。また、端末の取り回し(大きさ・重さ)を気にしないのであれば、Pixel 9も有力に思える(何より端末のデザインが新しくなるのが魅力的だ)*6。なお、廉価版モデルであるaシリーズは、同様にセンサーサイズの小ささ・端末の大きさ・ベゼルの太さが気になって選外となっている*7。
実をいうとPixel 8の取り回しは割としっくり来ているので、これを維持しつつ、魅力的な機種の登場を待つことにする*8。
*1:MNP後、povo2.0を経て現在はIIJmioを利用している。ちなみに、auからpovo2.0へのMNPは所謂ブラックリスト入りのリスクが低いと家電量販店の販売員に教えてもらった。真相のほどは定かではないが、これが真ならau→povo2.0→適当なMVNO→au…のループを2年間で回し、ディスカウントされた端末を使い続ける作戦がかなり経済的に思える
*2:少なくとも私が知っている範囲では、遅くとも8から
*3:とはいえ、私は隙間時間や移動時間でのネットサーフィン、LINEなどの連絡、Googleマップや乗換案内程度しか使わないライトユーザーなので、おそらく問題はない
*4:指紋センサーが光学(8)→超音波式(9-)になり精度向上した、というメリットもあるが、私は顔認証のユースケースが多く指紋認証でも困ったことは少なかった
*5:S25の新品未開封が11万弱で、2年前発売のS23の売価が5.3万円。つまり6万弱で2年間使える
*6:約8.7万円で入手でき、売価ベンチマークとしてのPixel 7が2.6万円で売れる。つまり6万円で2年間利用できる。個人的には、投げ売り要因で7万円を切って購入できればアリ
*7:とはいえ9aのフラットな筐体はスマートで魅力的だ
ホットスワップ対応のメカニカルキーボード Yunzii AL68 を購入してキーボード沼につま先を付ける
まとめ
Yunzii AL68というメカニカルキーボードを買った。キースイッチやキーキャップを付け替えて楽しんでいる。Cherry MX軸のメカニカルやHHKB (Happy Hacking Keyboard), Realforceという範囲までしか経験の無いユーザー(私がそうだった)にはぜひ一歩踏み出してほしい。
背景
ArchissのProgresTouch RETRO TINYというキーボードを長年使っており、軸の乗り換え*1や職場用を含めて合計3台も買うほどのファンだった。使い込んだからか、キーが戻るときの金属音*2が気になってきた。後継ラインナップとしてMaestroというシリーズもあるが、このシリーズには65%レイアウトのモデルがなく*3、次のキーボードが見つからなかった。
さらに調べてみると、Archissのキーボードは韓国のメーカーLEOPOLDによるOEMらしい。同社のラインナップにはFC660MBTという、ProgresTouch RETRO TINYと筐体がよく似たモデルがある。ただし、US配列モデルは日本で取り扱いがなく、海外から輸入したとしても技適が無い*4。
要件
大学の研究室時代にHHKB (Happy Hacking Keyboard) を触ってから、めっきりUS配列に慣れてしまっている。卓上をすっきりさせたいのと、マウスを置くスペースを中心寄りにしたいため、キーボードはコンパクトなレイアウトが望ましい。ただし、矢印キーは欲しい。カーソルの移動はEmacsキーバインド (Ctrl-F, B, P, N) で事足りるのだが、たまにこれらのキーバインドが効かないケースがあるからだ。同様に、Ctrl-Dが効かないケースもあるのでDeleteの生キーもあると安心。
Functionキーはなくても構わない。たまに装飾キーと合わせて押せればいい、くらいだ。ただし、他の観点が優れていれば、Functionキーのついている75%レイアウトもアリ。ちなみに75%レイアウトでは、65%レイアウトでのバッククオートとEscとで位置を取り合う(数字の"1"の左隣)問題が無くなるのは嬉しい。
探索
スタート:同類を見つける
「静か」の基準が人によって違うので(そもそも現在使っているのだって「静音」赤軸なのだ)、現役機=ProgresTouch RETRO TINYの金属音に言及している人を探し、その人が静かだと言っている機種を買う、が良さそうだ。
目論見通り発見できた(ありがたい!)。
【ARCHISS ProgresTouch TINY レビュー】最高の打鍵感。高級感の溢れるコンパクトなメカニカルキーボード。 | ガジェビーム
そして打鍵時に「カーン」というバネ音が聞こえやすい部分を除けば、本当に上質で使いやすいキーボードだと感じました。
そして静音キーボードも列挙してくれている(度々ありがたい!)。
静音性の高いゲーミングキーボードおすすめ3選。静かな軸・打鍵音についても徹底解説します。 | ガジェビーム
記事で紹介されていた機種で、要件にひっかかりそうなものは次の2つだった。
- Razer Huntsman Mini: 60%レイアウトで、矢印が無いのが気になる
- HyperX Alloy Origins Core RGB: 65%レイアウトのモデルがあり、この時点では最良の選択肢に見えた
2機種を家電量販店で触ってみた感じ、HyperX Alloy Originsはそこまで静かじゃない(Cherry MX赤軸相当)のと、キーキャップのフォントが好みではなかった。Huntsman Miniはキータッチが良好だったが、60%レイアウトなのでエンドゲームとはならなかった*5。
次の候補にホップする
初手と同様に、HyperX Alloy Originsのレビュー記事を探してみる。すると感覚が近いレビュワーが見つかった。
「HyperX Alloy Origins 65」レビュー。フルアルミボディで重厚感のある65%ゲーミングキーボード – DPQP | ゲーミングデバイスの総合情報サイト
シンプルな仕様で価格も安い*1のですが、これといって惹かれる部分がないのがやや残念です。少し予算を上げると、吸音フォームを組み込むことで打鍵感に優れたものや、ホットスワップ対応で拡張性に長けたものなど、他に良い選択肢が見つかります。余計な装飾や機能は不要という方にはいいかも。
吸音フォーム!そういうのもあるのか!
そういえば過去に読んだ以下の記事(大変参考になりました。ありがとうございます)にも書いてあったな。
キーボードの話 - naoya - Obsidian Publish
このレイヤリングで色々な素材を重ねつつガスケットマウント方式を採用するのが、昨今のメカニカルキーボードの定番方式になっていると思われます。ガスケットマウントは、ガスケットと呼ばれるクッション材でキーボードの基盤を浮かせて取り付ける方式で、これによりキーを底打ちした時に基盤辺のレイヤーが下に沈見込み、打鍵時のショックを吸収する効果があります。要するに長時間打っていても指が痛くならない。
この辺で、ガスケットマウントとホットスワップを今回のテーマにすることにした。単にマイナーアップデートな機種を買うよりも、新しい機能が加わったほうが財布の紐も緩むというものだ。ホットスワップをテーマに入れたのは、Redditあたりを読み漁っていて「キーボードの静音性に寄与するのは圧倒的にキースイッチ」という旨の言及を見かけたからだ*6。初期搭載のスイッチに満足できなくても付け替えればいいし、スイッチひとつの故障でキーボードを買い替える必要に迫られなくなる。
Epomaker x AULA F65
https://epomaker.jp/products/epomaker-x-aula-f65
有線・2.4GHz・Bluetoothの3種類で接続できる。1万円を切るコストパフォーマンスが魅力。ガスケットマウントとホットスワップまであってこれはすごい。白カラーの配色が可愛い(ただし私は、デスク上のガジェットの統一感からブラックを買う)。一方で、キーマップをカスタマイズするソフトウェアがWindowsのみの対応なのがネガティブ*7。
Glorious GMMK 2 65%
https://www.ask-corp.jp/products/glorious/keyboard/gmmk-2-65.html
有線のみ対応。ガスケットマウントが無い*8が、その他は問題なさそう。シンプルな筐体が良い。キーマップのカスタマイズはGlorious core(WinとMacの両方に対応)で可能。
Ducky One 3 SF 65%
https://www.fumo-shop.com/ducky-one3-classic-bw-rgb-sf.html
吸音フォームもあり、ホットスワップにも対応する。ネガティブな点は価格(2万円前後)、キーマップのカスタマイズ手段がなさそうで、かつFnキーの位置が覚えにくい。あとは筐体の下半分が白で、上半分が黒のツートンカラーが個人的に好みでなかった。
ここに来て、Fnキーの位置が要求に入ってくることが分かった。あるいは、キーマップのカスタマイズが可能であればよい。
Ducky ProjectD Tinker65
https://www.fumo-shop.com/ducky-tinker65-black.html
ガスケットマウントでホットスワップ対応。さらに、QMK/VIAでキーマップのカスタマイズも可能。One 3 SFの上位互換なのだが、国内・国外ともに取り扱いがなさそう。
Weikav Lucky65 V2
https://weikav.com/product/weikav-lucky65-v2/
キースイッチやキーキャップの付属しないベアボーンキット。ガスケットマウントで、ホットスワップとQMK/VIAに対応する。接続方式は有線・2.4GHz・Bluetoothの3種類に対応しているが、無線接続は日本で技適を取得していない(惜しい!)
ゴール:Yunzii AL68
https://www.yunzii.com/products/yunzii-al68-qmk-via-custom-mechanical-keyboard
Lucky65 V2と同等スペックで、日本で技適取得済み。ということでこれを購入した。
ファーストインプレッション
- 筐体が1.2kgくらいありずっしりしている。HHKB Type-Sの540gでもタイピング時にぐらつくことはなかったので正直もっと軽くても良かったが、持ち運びもしないのでまあ構わない
- ガスケットマウントは正直効果あるのかどうか体感できていない
- 購入時に搭載されていたキースイッチは Cocoa Cream V2 というリニアスイッチで、カツカツした打鍵音が楽しい。Cherry MX赤軸を使っていたころは単にスイッチの音がうるさいなと思っていたが、気持ちいい音はこれはこれで楽しいというのは新しい発見だった
- ライティング機能もあるが、あんまりこだわって設定していない
VIA設定
QMK/VIAに対応しており、キーマップをカスタマイズできるが、VIAで表示される各レイヤーや特殊キーが何に対応しているのかわからない。Redditで有志がまとめてくれている:https://www.reddit.com/r/keyboards/comments/1haboaa/yunzii_al68_via_configuration_details/
キースイッチ交換
Outemu Silent Peach V3という静音リニアスイッチを購入し早速取り替えてみた(70個で3000円を切る謎のコストパフォーマンス)。ほぼ無音のキーボードが出来上がって嬉しい。一方で、カツカツ・コトコトという打鍵音もなかなかいいという発見もあったので、たまに通常のスイッチに戻してみようとも思う。
*1:発売当初は静音赤軸が無かったが後に追加された
*2:バネ音だろうか。ピーンという感じ。M1ガーランドを彷彿とさせる
*3:メーカーに問い合わせしてみたが梨の礫だった
*4:そもそも発売が数年前らしく、海外でも取り扱いが少ない
*5:ただしそれ以外は概ね完璧だったので、矢印キーが特殊なバインドでもいいじゃん、となったら将来買うかもしれない
*6:じゃあガスケットマウントは要らなくない?となるのだが、まあ未経験なので触ってみたかったということで…
*7:Windows機も持っているが、普段使うのはMacOSなのだ
*8:後続機のGMMK 3シリーズはガスケットマウント搭載なのだが、65%レイアウトのモデルが無い
スケールとトレードオフ:「Googleのソフトウェアエンジニアリング―持続可能なプログラミングを支える技術、文化、プロセス」を読んだ

いわゆるビックテックの一角として不動の地位を確立しているGoogleの、ソフトウェアエンジニアリングに関するトピックを余すところなく書き詰めた一冊である。
本書はまず、「ソフトウェアエンジニアリングとは何か」から書き出されている(以下に引用)。言葉遣いや用語の定義にうるさい私としては、この構成に非常に好感が持てる。
Google社内でときに言われるのは、「ソフトウェアエンジニアリングとは時間で積分したプログラミングである」ということだ。
1章 ソフトウェアエンジニアリングとは何か
生産的にプログラミングをし続けることができる―書籍のタイトルにもなっている「持続可能なプログラミングを支える技術、文化、プロセス」を確立し改善し続けることが、ソフトウェアエンジニアリングだと言っている。単にコードやシステムを作成するのがプログラミングや開発だとしたら、それらを将来に渡って効率的に継続させる仕組みを考えるのがソフトウェアエンジニアリングなのだ。
プログラミングや開発を継続したとき、すなわち時間が経過すると何が起こるか。一般的には、プロダクトが成長し、組織やチームの規模が増大していく。この際になってもまだ、仕組みが効果的に機能することが重要なのだと本書は主張する。「スケール(する)」や「スケーラブル」というキーワードが頻出することからもそれは分かる。
また、そのような仕組みを構築していく上で、慎重かつ入念にトレードオフを決定していった様子も伺える。ここで改めて書くまでもないが、一般的な問題解決には「銀の弾丸」は存在せず、解決策ごとに長所と短所がある。コードレビュー、バージョン管理、テスト、CI/CDなどの多岐にわたるトピックについて、Google内部で起こった問題と、解決策および考慮したトレードオフが詳細に解説されており、ケーススタディとして非常に参考になる。
あとがきにもある通り、
Googleのソフトウェアエンジニアリングは、大規模かつ発展中のコードベースの開発と保守の方法における、並外れた実験であり続けてきた。
本書を通読すると、Googleのソフトウェアエンジニアリングが並外れていることが理解できる。また、その歴史やノウハウを惜しげもなく公開する行為に、Googleにとっては本書の内容はただの通過点であり、競合他社が真似をしたとしても追いつけないだろうという自信が垣間見えるようにも感じる。
以下は特に印象に残った箇所を引用する。トピックごとにまとめている。
文化
存続期間の長いプロジェクトでは、最初の決定が行われた後に方針を変更する能力があることが不可欠である場合が多い。そして、重要なのは、それが、決定者が間違いを認める権利を有していなければならないのを意味することだ。
1.3.5 決定を再考すること、間違うこと
ここだけでなく、機敏さ (aglie) をもって改善していくことが繰り返し強調されている。
Googleに何年も在籍しているエンジニアでも、やっていることの内容を把握していると感じていない領域が依然としてある。それでいいのた!「それが何か知らないので、説明してくれませんか」と言うことを恐れてはいけない。何か知らないものがあることを恐れるよりは、またとない機会が眠る領域として受け入れよう。
3.4.1 質問を尋ねよ
Googleのエンジニアは無敵なのかと思っていたが、ちょっとホッとする一節である。
組織の文化というものは、ドロドロした人間的なものであり、多くの企業では後付けで扱われるものである。しかしGoogleにおいて我々が確信しているのは、その環境の成果物(例えばコード)にのみ焦点を当てるより、まずは文化と環境に焦点を当てる方が良い結果につながるということだ。
3.7.1 知識共有の文化を養う
成果物よりも文化と環境が優先されるべき。言うは易く行うは難し。
コーディング・コードレビュー
自分という存在と、自分のコードとは別だ。
2.4.3 謙虚、尊敬、信頼の実践
いろいろな記事や書籍で言及されているが、これは大事。
Googleには非常に力強いコードレビュー文化があり、リーダビリティはそのような文化の自然な延長である。リーダビリティは、1人のエンジニアの情熱から始まり、生身の人間である専門家たちがGoogleの全エンジニアをメンタリングするという公式プログラムへと発展していった。
3.8.2 何故このプロセスがあるのか
プログラミング言語ごとにリーダビリティをチェックする担当が存在する。また、コードごとにそのオーナーが存在する。レビュープロセスでは、これらのメンバーによるレビューが通ってはじめて、PR(GoogleではCL: Change Listと言うらしい)がマージできる。こうすることで、コードの可読性が担保されるとともに、誰がオーナーか分からないコードが生まれにくくなる。
「小さな」変更とは通常、約200行までのコードに限定されるべきだ。
(中略)
Googleでの変更の大半は、約1日以内にレビューされることが期待されている(これはレビューが1日以内に終わることを必ずしも意味せず、最初のフィードバックが1日以内に提供されることを意味している)。
9.4.2 小さな変更を書け
PRの大きさ、レビューのレスポンスの早さの参考に。
変更説明というものは、1行目に要約としてその変更がどんな種類のものかを示すべきだ。
(中略)
最初の行は変更全体のようやくとなるべきだが、何が変更されているのか、そして何故変更されるのかの詳細についても説明が及ぶべきである。「バグ修正」という説明があるだけでは、レビュアーや、将来のコード考古学者にとっては助けにならない。
9.4.3 良い変更説明を書け
テスト
我々は上記のように区別しており、もっと伝統的な「ユニット」または「インテグレーション」の区別は用いていない。その理由は、我々がテストスイートに望む最も重要な特性は、テスト範囲とは無関係に、速度と決定性 (determinism) だからである。
11.2.1 テスト規模
Googleではテストを規模に応じて(特大・)大・中・小に分類している。確かに言われてみれば、「ユニット」と「インテグレーション」の区別を鵜呑みにしていたが、そうではない区別も考えられる。
信頼不能性が1%に接近すると、テストは価値を失い始めるということだ。
11.2.1 テスト規模
信頼不能なテストとは、非決定性要素によりたまに失敗するテスト。
何故、テストを書くことを命令として強制するところから始めなかったのだろうか。 テスト小グループは、テストに関する命令を出すようシニア幹部陣に求めることを検討したが、すぐにそれは行わないことに決めた。コードの開発方法についての強制は、どんなものであろうが、Googleの文化に真っ向から逆らうものであると同時に、おそらく進歩を鈍化させるものだ。それはどんな思想が強制されるかに関係ない。成功する思想は広まるものであるというのが我々の信念であり、したがって専念するべき点は、成功を実証してみせることとなった。
11.4.4 今日のテスト文化
文化の醸成についての良い示唆。強制するのではなく、試させて価値を感じさせてはじめて根付く。
・テストダブルより本物の実装が優先されるべきである。 ・テスト内で本物の実装が利用できないなら、フェイクが理想的な解法である場合が多い。 ・スタビングを使いすぎると、不明確で脆いテストにつながる。
13.10 要約
自分の場合、テストではすぐにモックを使う傾向にあるが、本物を使ってしまう方が良いとのこと。
ドキュメンテーション
Googleで最も成功を収めている取り組みは、ドキュメンテーションをコードのように扱うとともに、伝統的なエンジニアリングのワークフローへ組み込むというものであり、エンジニアが単純なドキュメントを書いて保守するのを楽にしている。
10章 ドキュメンテーション
「コードのように扱う」というのは良いやり方。具体的には次の通り。
Googleが取っているアプローチは、C++のAPIはそのリファレンスドキュメンテーションをヘッダーファイル内に存在させておくのがふさわしい、というものだ。他のリファレンスドキュメンテーションもまた、直接Java、Python、Goソースコードに埋め込まれている。
10.5.1 リファレンスドキュメンテーション
また、wikiベースのドキュメンテーションをしている組織は多いだろうが、Googleもかつてはそうだった。しかし、スケールの途中で問題が発生している。おそらく、多くの方にも見覚えのある光景なのではないだろうか。
wikiドキュメントには真のオーナーがいないため、多くのドキュメントが廃れていった。新ドキュメント追加に関するプロセスが施行されていなかったため、重複したドキュメントやドキュメント集が現れ始めた。GooWikiの名前空間はフラットで、誰もドキュメンテーション集をうまく階層化できなかった。
10.3 ドキュメンテーションはコードのようなものである
ランディングページ(ポータル)の存在が重要であるとも主張されている。
要は、ランディングページが必ず目的を明確に特定しているようにし、それからさらなる情報を得るための他のページへのリンクのみを含めるようにするのだ。もしランディングページ上で交通整理の警官以上のことをやっているものが何かあったら、そのランディングページは本来の仕事をしていない。
10.5.5 ランディングページ
バージョン管理
Googleでは、Piperと呼ばれる独自のVCSを利用している。GitHubのようなVSCとの大きな差異は、リポジトリのディレクトリやファイルごとにオーナーシップの概念が取り入れられていることのようだ。
Googleでは、VCSを掌握することで、オーナーシップと承認の概念をより明示的にすることができている。またその概念を、コミット操作の試行中ははVCSによって強制できる。
また、依存するコンポーネントやライブラリのバージョンを選ぶことができない。とんでもない話に思えるが、解説を読むと納得がいく。
「単一バージョンルール」は、組織の効率にとって驚くほど重要である。どこにコミットすべきか、あるいは何に依存すべきかについての選択の余地をなくすことで、著しい単純化を結果として得ることができる。
16.7 要約
CI
・CIシステムは、どんなテストを利用するべきか、またいつ利用すべきかを決定する。
(中略)
・CIは、早くて信頼性の高いテストがリポジトリー提出前に配置され、遅くて決定性の低いテストがリポジトリー提出後に配置されるように最適化されるべきである。
23章 継続的インテグレーション 23.4 要約
CIの勘所がよくまとまった要約。
CD
技術の状況が移り変わる速さと予測不可能性とを前提とすると、あらゆる製品にとって、競争的優位とは、迅速に市場への投入ができる能力の中に存在するものである。
24章 継続的デリバリー
リリーストレインと呼ばれる一定周期でのリリース作業が行われ、いかなる理由でもこれは延期されない。
リリースの責任の1つは、製品を開発者から守ることである。 トレードオフを行う際に、開発者が新機能をローンチすることについて感じる情熱と切迫感が、既存製品のユーザーエクスペリエンスに勝ることは、決してありえない。
24.7 チームの文化を変える:デプロイに規律を組み込む
コンピュート環境
データセンターの拡大は複雑な手動のプロセスで、特化したスキルセットを要し、(全マシンを用意した時点から)何週間もかかるので、内在的なリスクがあった。それにもかかわらずGoogleが管理するデータセンターの数が増加していることが意味するのは、データセンターの拡大が人間の介在を要しない自動プロセスとなっているモデルへGoogleが移行したということだ。
25.1 コンピュート環境を手なづける
「データセンターの拡大が人間の介在を要しない自動プロセスとなっている」というのは、とてつもない話だ。
マネジメント
マネジメントの仕事の定量化は、作ったウィジェットの数を数えるより難しい。だが自分のチームが満足かつ生産的でいられるようにすることは、マネジメントの仕事の重要な尺度である。とにかく、バナナを育てているのに林檎を数える罠に落ちてはならない。
5.2.1 恐れるべき唯一のものは……えっと、全てだ
管理職のみなさま、なにとぞ。
障害を取り除く助けになる答えの全てを知っている必要はないが、答えがわかる人々を知っているとたいてい役立つ。
5.5.4 障害を取り除け
人脈を作っておく意義。
このプロセスには3つの主なステップがある。まず、目隠しを特定しなければならない。次に、トレードオフを特定しなければならない。それから、決定を行って解法を反復しなければならない。
6.1.1 飛行機の比喩
ここでも「解法を反復」とある。一度決めたやり方は定期的に見直す。
よくある誤りは、チームに一般的問題ではなく特定製品を担当させることだ。
6.2.2 問題空間の分割
本当によくある誤り。視野を狭窄させてしまうだけでなく、モチベーションも下げる恐れがある。
つまり自分しかできない決定的に重要なものを意識して識別し、それらに完全に専念すべきだ。他の80%を落とすことを自身に明示的に許可しなければならない。
6.3.3 ボールを落とすことを学べ
改善のための計測
その利害関係者がそのデータを使わないのであれば、その計測プロジェクトは常に失敗だ。計測結果に基づいて具体的決定がなされるであろう場合にのみ、ソフトウェアプロセスの計測を行うべきである。
7.2 トリアージ:そもそも計測するほどの価値があるか
文章にしてみれば当たり前のように読めるが、これを守れていない計測もよく見かけるような…。
Partial Label Maskingでマルチラベル分類問題のデータ不均衡に対応する
まとめ
マルチラベル分類問題におけるデータ不均衡に対応する手法として、Partial Label Masking (PLM) が利用できる。同手法の概要は次の通り。
- サンプルごとに各クラスに対する損失関数を確率的にマスクすることで、アンダーサンプリングに似た効果を期待する
- 任意の損失関数に対して適用できる
- マスクする確率は、分類器がそのクラスをどれだけ過剰に/過小に予測しているかに応じて決める
論文
K. Duarte, Y. Rawat and M. Shah, "PLM: Partial Label Masking for Imbalanced Multi-Label Classification," CVPR2021 Workshops, pp. 2739-2748.
Partial Label Masking (PLM)
いま、 番目のサンプルについて、
を目的変数(真値)、ネットワークの推論結果
と書くとき、すべてのクラス(
個ある)に対する損失関数は次のように書ける。
Partial Label Masking (PLM) では、特定のクラスに対する損失関数をマスクしてしまう。具体的には、2値のマスク]を前述の損失関数に適用する。すなわち損失関数は以下のようになる。
式から明らかなように、PLMは任意の損失関数に対して適用できる。
適切にマスクを設定することで、損失関数に寄与する、それぞれのクラスに対するサンプル数を等しくできる。これはアンダーサンプリングの考え方と似ている。多クラス分類 (Multi-class classification) 問題では、アンダーサンプリングにより学習データ内のラベルの偏りを軽減することができる。しかしながら、マルチラベル分類 (Multi-label classification) では、同一のサンプルにおいて頻出なラベルと希少なラベルが共起する場合があり、アンダーサンプリングによりこのようなサンプルを取り除いても不均衡の解消にはつながらない。PLMを使えば、このようなラベルの共起に対応しつつ、学習データ内のラベル不均衡を解消できる。
マスクの生成
マスクの生成では、正例の負例に対する比率 を考える。この比率は、学習データに含まれる正例の数
を負例の数
で割ることで算出する。また、クラスの過剰あるいは過小な予測を最小化する、理想的な比率
を仮定する。すると、マスクは確率的な関数として次のように書ける。
ここで、]は確率
で1に、確率
で0になる関数である。上式はすなわち、正例が過剰に予測されている(ネットワークが入力を正例だと推論する傾向にある)なら、正例のうち
だけを損失関数の計算に使うことを表している。反対に、正例が過小に予測されるなら(負例が過剰に予測されるなら)、負例のうち
だけを損失関数の計算に使う。これにより、それぞれのクラスについて、正例と負例の比率を指定しながら分類器(ネットワーク)を訓練できる。
比率の適応的選定
では、理想的な比率 をどのように選べば良いだろうか。簡単な方法としては、学習データにて各クラスの比率を計算し、それらを平均することが考えられる。しかしながらこの方法は、著者らによると、うまく機能しない場合(データセット)があるそうだ。そこで著者らは、分類器の予測結果の確率分布から適応的にこの比率を推定する手法を提案している。
あるクラス の正例と負例について、分類器が出力する確率の分布をそれぞれ
とする。分布は
個のビンに分け、離散的に扱う。また、学習データ(真値)の分布を
とする。ただし、学習データでは確率が分布しているわけではなく、正例あるいは負例であることが確定しているので、確率1または0を含むビンにすべてのデータが入っている。
分類器が出力する確率の分布と、真値の分布とのずれをKullback-Leibler divergence(KLダイバージェンス、KL情報量とも)で表す:
さらに、これら標準化して および
を得る。
が正のとき、分類器はクラス
を過小に予測している傾向にある(反対に、負のとき、過剰に予測している)。この逆が
に成り立つ。
と
がバランスするように
を更新すればよい。エポック
における
を、ひとつ前のエポックでの
と
の差
を用いて以下のように更新する:
ここで、 は比率を更新する割合を定めるハイパーパラメータである。
モデル訓練のループ
モデルを訓練するループは以下のようになる。
を使ってマスク
を生成する
- すべてのミニバッチに対して、マスクした損失関数を使ってパラメータを更新する(一般的なニューラルネットと同様に、順伝搬→逆伝搬を使う)。このとき、順伝搬した結果(推論結果である確率分布)
を保存しておく
- 順伝搬した結果
から、
を算出する
を更新する
実験結果
素朴なBinary cross entropy, Focal loss, サンプル数の逆数での重み付けといった手法と性能を比較している。分量が多いため、詳細は元論文を参照されたい。
分類器の信頼度を使うならtemperature scalingでキャリブレーションしよう
論文
C. Guo, G. Pleiss, Y. Sun and K. Q. Weinberger, "On calibration of modern neural networks," ICML2017, pp. 1321-1330.
なお、本記事中の図は、論文から引用したものである。
まとめ
論文を読んで得られた知見をまとめると以下の通り。
- ResNetといった現代のニューラルネットワークでは、分類性能を上げるためのアーキテクチャや工夫によってミスキャリブレーションが発生しがちである(信頼度が正解率を正確に表していない)
- モデルの信頼度を利用するアプリケーションなら、信頼度のキャリブレーションをするべき。キャリブレーションにはtemperature scalingを使うのが良い
概要
分類器が出力する信頼度 (confidence) が、分類結果が真に正しい可能性を表すように補正する (calibrate) ことを、信頼度キャリブレーション (confidence calibration) と呼ぶ。分類器が適切にキャリブレーションされていることは、自動運転や医療など広いアプリケーションで重要である。
著者らは、現代のニューラルネットワークは、一昔前のものと比べると、キャリブレーションが不十分であることを発見した。また、ネットワークの深さ、幅、重み減衰 (weight decay), バッチノーマリゼーション (Batch Normalization) がキャリブレーションに重要な影響を与えることを観測した。
いくつかの後処理 (post-processing) キャリブレーション手法について、画像や文書の分類データセットと最新のアーキテクチャを用いて評価した。この評価を通して、temperature scalingが有効な手法であることを示した。
信頼度キャリブレーションの評価指標
Reliability diagrams

分類器のキャリブレーションの良し悪しを視覚的に表現にしたものがReliability diagramである(図の下段にあるものが該当する)。同図は、あるデータセットにおける推論結果(分類の正解・不正解と、その際の信頼度)を用いて作成できる。横軸は信頼度のビン (bin) で、ビンの分割数は適当な数を指定する(図では
)。縦軸は、それぞれのビンの正解率 (Accuracy) である。すなわち、ビンに入る分類結果のうち、正解であるものの割合である。
分類器が完璧にキャリブレーションされている (perfectly calibrated) とき、正解率は信頼度の恒等関数 (identity function) になる。このときReliability diagramでは、各ビンの棒グラフが、図の右下半分の三角形をちょうど占めるようになる。
ちなみに、Reliability diagramと等価な図としてCalibration curveがある。同図は、Reliability diagramの各ビンの頂点をつないだ折れ線グラフである。scikit-learnにはCalibration curveを描くための関数が存在する:sklearn.calibration.calibration_curve — scikit-learn 0.24.1 documentation
Expected Calibration Error (ECE)
分類器のキャリブレーションの良し悪しをスカラーで表現したものがExpected Calibration Error (ECE) である。Reliability diagramは良し悪しが視覚的に分かりやすいものの、比較の上ではECEのように定量的な表現の方が有益である。ECEは、Reliability diagramの各ビンにおける正解率と信頼度の差を、重み付き平均することで算出できる。
ECEは重み付き平均を用いるが、重み付き平均ではなく最大値を取ることもできる。このように算出された指標はMaximum Calibration Error (MCE) と呼ばれる。信頼度と正解率の差異がクリティカルになるアプリケーションでは、MCEを用いることもある。
Negative Log Likelihood (NLL)
Negative log likelihood (NLL) は、確率的なモデルの品質を測る標準的な尺度である。深層学習では交差エントロピー損失 (cross-entropy loss) としても知られる。確率モデル とn個のデータが与えられたとき、NLLは次式のように書ける。
NLLが最小化される必要十分条件は、 が真の分布
を復元していることである。
ミスキャリブレーションの観察

上図は、ネットワークのアーキテクチャを変更したり学習上の工夫を入れたりしたときの、不正解率 (error) およびECEが受ける影響を表している。以下が読み取れる。
- ネットワークの深さを増すと、errorは下がるが、ECEは上がる
- 幅を増すと、やはりerrorは下がるが、ECEは上がる
- Batch Normalizationを適用すると、errorは下がるがECEは上がる
- weight decayの重みを増すと、errorもECEも下がる。なお、右端でerrorやECEが悪化しているのは、正則化がかかりすぎているためだと考えられる
NLLの過適合
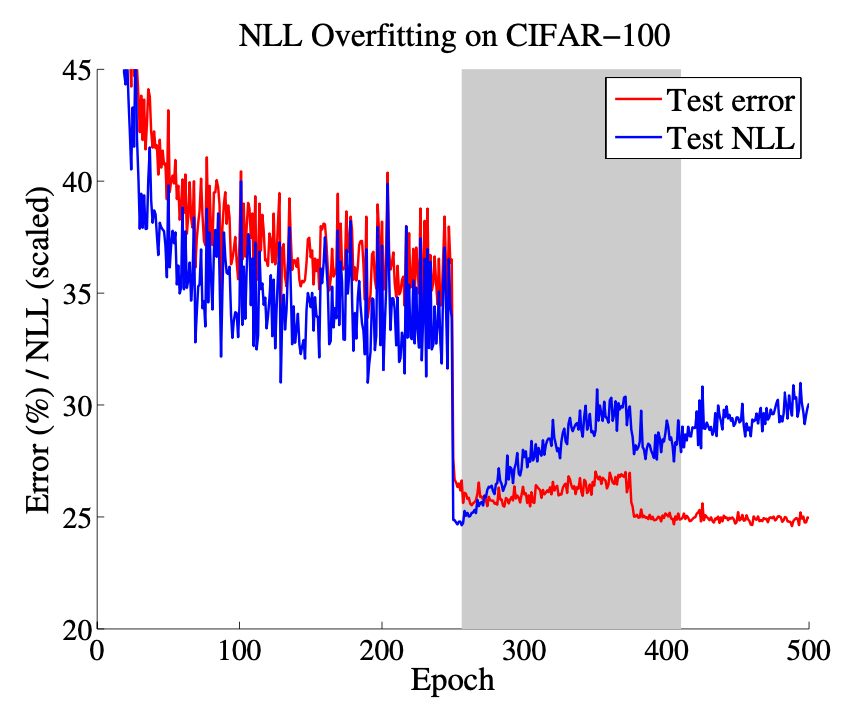
上図はResNet-110をCIFAR-100で訓練したときの、test setにおけるerrorとNLLを表す。なお、epoch 250と375のそれぞれでlearning rateを1/10に落としている。グレーの領域は、validation setでerrorおよびlossが最良であった区間を表す。
著者らは、正解率(あるいはerror)とNLLとの間の断絶を観測した。すなわち、ニューラルネットワークは、0/1 lossに過適合せずにNLLに過適合できる、ということだ。
Epochを追うごとに、test errorが下がる一方で、test NLLが増加している。これは、次の2つを示唆している:ニューラルネットワークは、(1) 0/1 lossに過適合せずにNLLに過適合できる、(2) well-modeled probability(信頼度が正解率を表すこと)を犠牲に分類性能を上げている(errorを下げている)。
注:論文中でいきなり"0/1 loss"なる用語が出現するなど、やや意味が取れない部分があったので、自分なりに考えてみる。Deep Neural Network (DNN) の学習で用いるクロスエントロピー損失は、正解クラスに対する信頼度を各データについて合計することで求まる。すなわち、
を計算している。ここで、i番目のデータに対し、真のラベル (0/1) を, 分類器が出力した信頼度を
とする。論文では、分類結果が真のラベルと一致しているか、すなわち真のラベルに対応するクラスに最大の信頼度を割り振れているかどうか、を0/1 lossと呼び、その信頼度が真の確率分布に近いかどうか、をNLL lossと呼んでいるのだと推測する。
信頼度キャリブレーションの手法
二値分類
Histogram binning
分類器が出力した信頼度をビンに分け、ビンごとに補正後の出力を決める。補正後の出力は、ビンに入った信頼度の平均とする。
Isotonic regression
補正前後の信頼度をマッピングする関数を学習する。任意の2つの信頼度は、補正前後で大小関係が前後しないという拘束条件をかける。ビンの区切りと出力を一緒に最適化しているという点で、histogram binningの一般化といえる。なお、scikit-learnに実装がある:sklearn.isotonic.IsotonicRegression — scikit-learn 0.24.1 documentation
Bayesian Binning into Quantiles (BBQ)
Histogram binningをBayesian model averagingによって一般化した手法らしいが、後述の実験によるとあまり有効ではないようなので省略。
Platt scaling
補正前の出力に対してロジスティック回帰を適用し、補正後の出力を求める。ロジスティック回帰のパラメータ推定にはvalidation setを用いる。なお、scikit-learnでは、SVMにPlatt scalingを適用してキャリブレーションした信頼度を出力するオプションがある:sklearn.svm.SVC — scikit-learn 0.24.1 documentation
多クラスへの拡張
ここまではクラス数の場合を述べてきたが、これを
に拡張する。
Binning methodの拡張
K個のone-versus-all問題として解く。すなわち、各クラスについてhistogram binningを行い、キャリブレーションされた信頼度を得る。キャリブレーションされた信頼度が最も高いクラスを分類結果とする。また、信頼度は正規化して最終的な出力とする(各クラスに対するキャリブレーション後の信頼度の総和で割る)。このアプローチはisotonic regressionやBBQにも適用できる。
Matrix and vector scaling
Matrix scalingは、Platt scalingを多クラスに拡張したものである。softmax層に入力される前にロジットベクトルを
を重み
とバイアス
でスケールする:
ここで、はキャリブレーションされた信頼度、
はクラスのインデックスである。
と
はvalidation setとNLLを用いて最適化する。
を対角行列にしたものをvector scalingと呼ぶ。
Temperature scaling
Temperature scalingは、Platt scalingのシンプルな拡張である。ロジットベクトルz_iが与えられたとき、すべてのクラスに対する信頼度をスカラーT>0でスケールする:
は温度 (temperature) とも呼ばれる。matrix/vector scalingのパラメータと同様に、
はvalidation setとNLLで最適化する。
はsoftmaxの出力が最大となる位置(クラス)を変えない。言い換えると、temperature scalingは分類器の分類結果を変えないし、分類器の正解率を下げることもない。※一方で、binningに基づく手法はそうではない
信頼度キャリブレーションの評価
キャリブレーション結果

画像・文書の分類データセットにおける、ResNetを始めとしたモデルについて、補正前後のECEを測定した結果が上表である。区切り線の上側が画像の分類データセットで、下側が文書のものである。
ほとんどのケースでミスキャリブレーションは発生する(ECEは4〜10%程度)。例外はSVHNとReutersで、ECEはどちらも1%を切っている。これらのデータセットでは、不正解率も低い(それぞれ1.98%, 2.97%)。また、ミスキャリブレーションはネットワークのアーキテクチャに依存しない。ResNetのようにskip-connectionを持つかどうか、reccurent(再帰的)かどうか、などは関係ない。
Temperature scalingは、そのシンプルさにもかかわらず、画像の分類データセットでその他の手法に優る。文章のデータセットでも他の手法と同等である。Matrix/vector scalingはtemperature scalingを一般化した手法だが、temperature scalingに劣るケースが多い。これは、ミスキャリブレーションが本質的に低次元であることを示唆している。
Temperature scalingでECEが唯一改善しなかったのは、データセットReuterである(temperature scalingに限らず、vector scalingを除くすべての手法で改善できていない)。キャリブレーション前のECEが良好で (< 1%), キャリブレーションの余地がなかったと考えられる。
Matrix scalingは、Birds, Cars, CIFAR-100などのクラスの多いデータセットで成績が悪かった。さらに、ImageNetのようなデータセットでは収束しなかった。これは、クラス数の二乗でパラメータ数が増え、過学習するためである。
Binningに基づく手法はほとんどのデータセットでECEを改善したが、temperature scalingよりも優れない。また、分類結果を変え、分類性能を低下させる傾向がある。これらの手法の中でもhistgram binningは最も単純なものだが、より一般的な手法であるisotonic regressionやBBQよりもECE改善の面で優れている。これは、シンプルなモデルでキャリブレーションを行うのが良いという著者らの主張を裏付けている。
計算時間
(本実験で扱った)すべての手法の計算時間は、validation setのデータ数に対して線形にスケールする。temperature scalingは、1次元の凸最適化問題を解くため、最も速い。共役勾配法 (conjugate gradient) ソルバーを用いた場合、10回のイテレーション以内で最適解が求まる。素朴な線形探索 (linear search) を使ってさえ、他のすべての手法よりも速い。
参考文献
- 論文メモ On Calibration of Modern Neural Networks - Coda
- 同じ論文を読んだ方のメモ。簡単にまとまっていて分かりやすい
- 確率予測とCalibrationについて - 機械学習 Memo φ(・ω・ )
- 分類器のキャリブレーションに関する知見が網羅的にまとまっている
次に読む
- M. Kull, M. Perello-Nieto, M. Kängsepp, H. Song and P. Flach, "Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with Dirichlet calibration," NeurIPS2019.
- 非ニューラルネットワークかつマルチクラス分類を行う分類器をキャリブレーションする手法らしい
- S. Seo, P. H. Seo and B. Han, "Learning for single-shot confidence calibration in deep neural networks through stochastic inferences," CVPR2019, pp. 9030-9038.
不均衡データはundersampling+baggingしろ、という話
まとめ
不均衡なデータの分類器を学習するときはundersampling+baggingすべし。 特に以下の場合に、コストを調整する手法やoversampling(SMOTEなど)に対して優れている。
- 次元数が多い
- 少数クラスのデータ数(の比率)が少ない
- 学習データの規模が小さい
きっかけ
不均衡なデータを扱う問題に遭遇したので、先人たちの工夫について調べていたところ、以下のツイートを発見した。
imbalanced data に対する対処を勉強していたのだけど,[Wallace et al. ICDM'11] https://t.co/ltQ942lKPm … で「undersampling + bagging をせよ」という結論が出ていた.
— ™ (@tmaehara) 2017年7月29日
ここで紹介されている論文、およびその解説記事などを読み漁った。本記事ではそれらをつまみ食いした知見をまとめる。
論文
Byron C Wallace, Kevin Small, Carla E Brodley and Thomas A Trikalinos, "Class imbalance, redux," Proc. Int'l Conf. Data Mining (ICDM), pp. 754–763. 2011.
不均衡データによって生じる分類器のバイアス
まず、不均衡データによって分類器にバイアスが生じる様子を示す。

簡単のため線形分類器で2値分類をする場合を考える。正規分布のような山は、それぞれ正例と負例の真の分布を表す(左側が正例、右側が負例である)。これらの分布から取り出されたサンプルを、バツ印(正例)と四角(負例)で表している。図から明らかなように、正例がminority classである。さらに、識別境界を と表し、その左側の領域を
, 右側の領域を
と記す。
ここで、理想的な境界は、真の分布から とわかる。しかしながら、サンプルから(例えばマージン最大化で)学習された境界は、点線で示された
のようにバイアスがかかってしまう。
バイアスが発生する条件
次に、このようなバイアスが発生する条件を考える。
データセットに含まれる正例の集合を , 負例の集合を
とする。データセット
で学習したときの経験損失
は、偽陰性と偽陽性のコスト(ペナルティ)をそれぞれ
とすると、
となる。要は、偽陰性の数×コストと、偽陽性の数×コストの和である。このとき、バイアスが生じる必要十分条件は、次のように書ける。
すなわち、理想的な境界 の右側にあるすべてのどんな境界よりも、経験損失を小さくする境界が左側に存在するとき、バイアスが生じると言っている。
このようにバイアスが発生する、すなわち が存在する条件を考える。正例と負例の真の分布をそれぞれ
とし、prevalence(母集団における正例の割合)を
とすると、
のとき、 が存在しうる。
バイアスを低減するためのアンダーサンプリング、およびbagging
上式を成立しにくくするためには、とすればよい。すなわち、majority classをアンダーサンプリングし、クラス間のデータ数を揃えればよい。
アンダーサンプリングはバイアスを低減できる一方で、モデルのvarianceは増えてしまう(学習される識別境界が、ランダムサンプリングによってばらつくことを言っている)。このvarianceを抑えるために、baggingするのがよい。
コストの調整やオーバーサンプリング
コストの調整
不均衡データに対する対処法として、偽陰性や偽陽性のコストに重みをつける手法が知られている。しかしながら、このような重み付きコストが効果を発揮しにくい場合がある。
いま、 (同じ重み)として、ある境界
が学習できたとする。ここで、
を
倍することを考える。このコスト増加によって境界
が動くのは、
が1つ以上の偽陰性をもたらす場合だけである。このような偽陰性のデータが無いとき、
にかかわらず、
は既に損失関数を最小化している。なお、
を動かすような偽陰性が観測される確率は次のように書ける。
上式より、以下のような場合に の増加が
を動かす、すなわちバイアスの低減に寄与しにくいことがわかる。
- prevalence
が低い場合(正例の割合が小さい場合)
- データセットの規模が小さい場合(データ数
が少ない場合)
また、 も寄与を左右する。具体的には、理想的な境界
の周辺で
が密である場合に、コストの調整はバイアス低減に寄与しやすい。
オーバーサンプリング (SMOTE)
重み付きコストの他に、SMOTEのようなオーバーサンプリングに基づく手法も知られている。SMOTEでは、minority classのデータ同士で近いものの間に新しいデータを内挿することで、データ数を増やす。したがって、SMOTEで新たに生成されるデータは、既に存在するminorityなデータの凸包 (convex hull) の外側に現れることはない。これより、SMOTEがバイアスの低減に効果を発揮するのは、コストを調整する手法が効果を発揮する場合と同様である。SMOTEによって新しく生成されたデータが境界 を動かすには、このデータが偽陰性とならなければいけない。
実験
論文ではシミュレーションデータや実際のデータセットで実験し、ここまで述べた理論の裏付けをしている。内容は省略。
関連トピック
予測確率のバイアス
アンダーサンプリングによって、分類器の予測確率にバイアスが生じてしまう。アプリケーションにて予測確率が重要な場合は、キャリブレーションすべきとのこと。
参考:ダウンサンプリングによる予測確率のバイアス - sola
DNN (Deep Neural Network) への適用
モデルがDNNの場合は、訓練や推論の時間的にもモデルの容量的にもbaggingを単純に適用するのは難しいことが多い。これに対して、ミニバッチ内でアンダーサンプリングを行うことで、似たような効果があるようだ。
参考:不均衡データ分類問題をDNNで解くときの under sampling + bagging 的なアプローチ - BASEプロダクトチームブログ
参考文献
- メモ Class Imbalance, Redux - Coda
- 冒頭の論文を非常に簡潔かつわかりやすくまとめている。
- 論文読んだ「Class Imbalance, Redux」 - Speaker Deck
- こちらもよくまとまっている。
- Class Imbalance, Redux
- 論文著者による発表または講義のためのスライドにようだ。これも図が多めでわかりやすい。
- 不均衡データをundersampling + baggingで補正すると汎化性能も確保できて良さそう - 渋谷駅前で働くデータサイエンティストのブログ
- Rによる実験コードおよび結果。