分類器の信頼度を使うならtemperature scalingでキャリブレーションしよう
論文
C. Guo, G. Pleiss, Y. Sun and K. Q. Weinberger, "On calibration of modern neural networks," ICML2017, pp. 1321-1330.
なお、本記事中の図は、論文から引用したものである。
まとめ
論文を読んで得られた知見をまとめると以下の通り。
- ResNetといった現代のニューラルネットワークでは、分類性能を上げるためのアーキテクチャや工夫によってミスキャリブレーションが発生しがちである(信頼度が正解率を正確に表していない)
- モデルの信頼度を利用するアプリケーションなら、信頼度のキャリブレーションをするべき。キャリブレーションにはtemperature scalingを使うのが良い
概要
分類器が出力する信頼度 (confidence) が、分類結果が真に正しい可能性を表すように補正する (calibrate) ことを、信頼度キャリブレーション (confidence calibration) と呼ぶ。分類器が適切にキャリブレーションされていることは、自動運転や医療など広いアプリケーションで重要である。
著者らは、現代のニューラルネットワークは、一昔前のものと比べると、キャリブレーションが不十分であることを発見した。また、ネットワークの深さ、幅、重み減衰 (weight decay), バッチノーマリゼーション (Batch Normalization) がキャリブレーションに重要な影響を与えることを観測した。
いくつかの後処理 (post-processing) キャリブレーション手法について、画像や文書の分類データセットと最新のアーキテクチャを用いて評価した。この評価を通して、temperature scalingが有効な手法であることを示した。
信頼度キャリブレーションの評価指標
Reliability diagrams

分類器のキャリブレーションの良し悪しを視覚的に表現にしたものがReliability diagramである(図の下段にあるものが該当する)。同図は、あるデータセットにおける推論結果(分類の正解・不正解と、その際の信頼度)を用いて作成できる。横軸は信頼度のビン (bin) で、ビンの分割数は適当な数を指定する(図では
)。縦軸は、それぞれのビンの正解率 (Accuracy) である。すなわち、ビンに入る分類結果のうち、正解であるものの割合である。
分類器が完璧にキャリブレーションされている (perfectly calibrated) とき、正解率は信頼度の恒等関数 (identity function) になる。このときReliability diagramでは、各ビンの棒グラフが、図の右下半分の三角形をちょうど占めるようになる。
ちなみに、Reliability diagramと等価な図としてCalibration curveがある。同図は、Reliability diagramの各ビンの頂点をつないだ折れ線グラフである。scikit-learnにはCalibration curveを描くための関数が存在する:sklearn.calibration.calibration_curve — scikit-learn 0.24.1 documentation
Expected Calibration Error (ECE)
分類器のキャリブレーションの良し悪しをスカラーで表現したものがExpected Calibration Error (ECE) である。Reliability diagramは良し悪しが視覚的に分かりやすいものの、比較の上ではECEのように定量的な表現の方が有益である。ECEは、Reliability diagramの各ビンにおける正解率と信頼度の差を、重み付き平均することで算出できる。
ECEは重み付き平均を用いるが、重み付き平均ではなく最大値を取ることもできる。このように算出された指標はMaximum Calibration Error (MCE) と呼ばれる。信頼度と正解率の差異がクリティカルになるアプリケーションでは、MCEを用いることもある。
Negative Log Likelihood (NLL)
Negative log likelihood (NLL) は、確率的なモデルの品質を測る標準的な尺度である。深層学習では交差エントロピー損失 (cross-entropy loss) としても知られる。確率モデル とn個のデータが与えられたとき、NLLは次式のように書ける。
NLLが最小化される必要十分条件は、 が真の分布
を復元していることである。
ミスキャリブレーションの観察

上図は、ネットワークのアーキテクチャを変更したり学習上の工夫を入れたりしたときの、不正解率 (error) およびECEが受ける影響を表している。以下が読み取れる。
- ネットワークの深さを増すと、errorは下がるが、ECEは上がる
- 幅を増すと、やはりerrorは下がるが、ECEは上がる
- Batch Normalizationを適用すると、errorは下がるがECEは上がる
- weight decayの重みを増すと、errorもECEも下がる。なお、右端でerrorやECEが悪化しているのは、正則化がかかりすぎているためだと考えられる
NLLの過適合
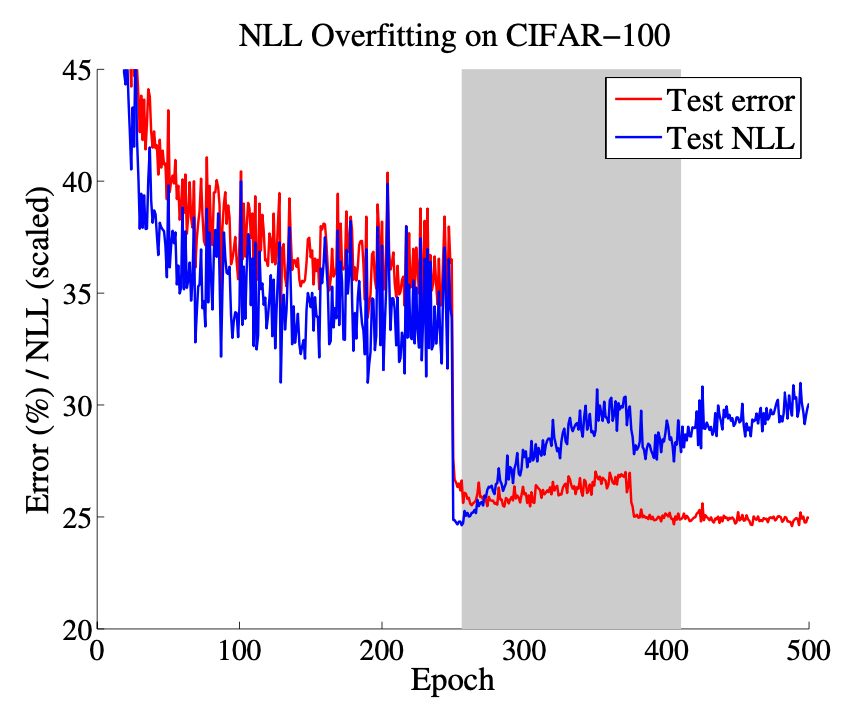
上図はResNet-110をCIFAR-100で訓練したときの、test setにおけるerrorとNLLを表す。なお、epoch 250と375のそれぞれでlearning rateを1/10に落としている。グレーの領域は、validation setでerrorおよびlossが最良であった区間を表す。
著者らは、正解率(あるいはerror)とNLLとの間の断絶を観測した。すなわち、ニューラルネットワークは、0/1 lossに過適合せずにNLLに過適合できる、ということだ。
Epochを追うごとに、test errorが下がる一方で、test NLLが増加している。これは、次の2つを示唆している:ニューラルネットワークは、(1) 0/1 lossに過適合せずにNLLに過適合できる、(2) well-modeled probability(信頼度が正解率を表すこと)を犠牲に分類性能を上げている(errorを下げている)。
注:論文中でいきなり"0/1 loss"なる用語が出現するなど、やや意味が取れない部分があったので、自分なりに考えてみる。Deep Neural Network (DNN) の学習で用いるクロスエントロピー損失は、正解クラスに対する信頼度を各データについて合計することで求まる。すなわち、
を計算している。ここで、i番目のデータに対し、真のラベル (0/1) を, 分類器が出力した信頼度を
とする。論文では、分類結果が真のラベルと一致しているか、すなわち真のラベルに対応するクラスに最大の信頼度を割り振れているかどうか、を0/1 lossと呼び、その信頼度が真の確率分布に近いかどうか、をNLL lossと呼んでいるのだと推測する。
信頼度キャリブレーションの手法
二値分類
Histogram binning
分類器が出力した信頼度をビンに分け、ビンごとに補正後の出力を決める。補正後の出力は、ビンに入った信頼度の平均とする。
Isotonic regression
補正前後の信頼度をマッピングする関数を学習する。任意の2つの信頼度は、補正前後で大小関係が前後しないという拘束条件をかける。ビンの区切りと出力を一緒に最適化しているという点で、histogram binningの一般化といえる。なお、scikit-learnに実装がある:sklearn.isotonic.IsotonicRegression — scikit-learn 0.24.1 documentation
Bayesian Binning into Quantiles (BBQ)
Histogram binningをBayesian model averagingによって一般化した手法らしいが、後述の実験によるとあまり有効ではないようなので省略。
Platt scaling
補正前の出力に対してロジスティック回帰を適用し、補正後の出力を求める。ロジスティック回帰のパラメータ推定にはvalidation setを用いる。なお、scikit-learnでは、SVMにPlatt scalingを適用してキャリブレーションした信頼度を出力するオプションがある:sklearn.svm.SVC — scikit-learn 0.24.1 documentation
多クラスへの拡張
ここまではクラス数の場合を述べてきたが、これを
に拡張する。
Binning methodの拡張
K個のone-versus-all問題として解く。すなわち、各クラスについてhistogram binningを行い、キャリブレーションされた信頼度を得る。キャリブレーションされた信頼度が最も高いクラスを分類結果とする。また、信頼度は正規化して最終的な出力とする(各クラスに対するキャリブレーション後の信頼度の総和で割る)。このアプローチはisotonic regressionやBBQにも適用できる。
Matrix and vector scaling
Matrix scalingは、Platt scalingを多クラスに拡張したものである。softmax層に入力される前にロジットベクトルを
を重み
とバイアス
でスケールする:
ここで、はキャリブレーションされた信頼度、
はクラスのインデックスである。
と
はvalidation setとNLLを用いて最適化する。
を対角行列にしたものをvector scalingと呼ぶ。
Temperature scaling
Temperature scalingは、Platt scalingのシンプルな拡張である。ロジットベクトルz_iが与えられたとき、すべてのクラスに対する信頼度をスカラーT>0でスケールする:
は温度 (temperature) とも呼ばれる。matrix/vector scalingのパラメータと同様に、
はvalidation setとNLLで最適化する。
はsoftmaxの出力が最大となる位置(クラス)を変えない。言い換えると、temperature scalingは分類器の分類結果を変えないし、分類器の正解率を下げることもない。※一方で、binningに基づく手法はそうではない
信頼度キャリブレーションの評価
キャリブレーション結果

画像・文書の分類データセットにおける、ResNetを始めとしたモデルについて、補正前後のECEを測定した結果が上表である。区切り線の上側が画像の分類データセットで、下側が文書のものである。
ほとんどのケースでミスキャリブレーションは発生する(ECEは4〜10%程度)。例外はSVHNとReutersで、ECEはどちらも1%を切っている。これらのデータセットでは、不正解率も低い(それぞれ1.98%, 2.97%)。また、ミスキャリブレーションはネットワークのアーキテクチャに依存しない。ResNetのようにskip-connectionを持つかどうか、reccurent(再帰的)かどうか、などは関係ない。
Temperature scalingは、そのシンプルさにもかかわらず、画像の分類データセットでその他の手法に優る。文章のデータセットでも他の手法と同等である。Matrix/vector scalingはtemperature scalingを一般化した手法だが、temperature scalingに劣るケースが多い。これは、ミスキャリブレーションが本質的に低次元であることを示唆している。
Temperature scalingでECEが唯一改善しなかったのは、データセットReuterである(temperature scalingに限らず、vector scalingを除くすべての手法で改善できていない)。キャリブレーション前のECEが良好で (< 1%), キャリブレーションの余地がなかったと考えられる。
Matrix scalingは、Birds, Cars, CIFAR-100などのクラスの多いデータセットで成績が悪かった。さらに、ImageNetのようなデータセットでは収束しなかった。これは、クラス数の二乗でパラメータ数が増え、過学習するためである。
Binningに基づく手法はほとんどのデータセットでECEを改善したが、temperature scalingよりも優れない。また、分類結果を変え、分類性能を低下させる傾向がある。これらの手法の中でもhistgram binningは最も単純なものだが、より一般的な手法であるisotonic regressionやBBQよりもECE改善の面で優れている。これは、シンプルなモデルでキャリブレーションを行うのが良いという著者らの主張を裏付けている。
計算時間
(本実験で扱った)すべての手法の計算時間は、validation setのデータ数に対して線形にスケールする。temperature scalingは、1次元の凸最適化問題を解くため、最も速い。共役勾配法 (conjugate gradient) ソルバーを用いた場合、10回のイテレーション以内で最適解が求まる。素朴な線形探索 (linear search) を使ってさえ、他のすべての手法よりも速い。
参考文献
- 論文メモ On Calibration of Modern Neural Networks - Coda
- 同じ論文を読んだ方のメモ。簡単にまとまっていて分かりやすい
- 確率予測とCalibrationについて - 機械学習 Memo φ(・ω・ )
- 分類器のキャリブレーションに関する知見が網羅的にまとまっている
次に読む
- M. Kull, M. Perello-Nieto, M. Kängsepp, H. Song and P. Flach, "Beyond temperature scaling: Obtaining well-calibrated multiclass probabilities with Dirichlet calibration," NeurIPS2019.
- 非ニューラルネットワークかつマルチクラス分類を行う分類器をキャリブレーションする手法らしい
- S. Seo, P. H. Seo and B. Han, "Learning for single-shot confidence calibration in deep neural networks through stochastic inferences," CVPR2019, pp. 9030-9038.